
又是一起抓狂的内存案例
前言
今下午在摸鱼的时候,又遇到一起数据库主机夯死导致数据库异常的问题。
现象
故障的时间点在 18 号下午,今天同事转了邮件过来,让分析一下根因。
还是老样子,先从操作系统层面分析。在我们的环境中有记录OSW,所以还是比较方便的。首先看看ps,故障前后进程的状态至关重要。
此处做了精简,👆🏻可以看到故障时间点附近 PostgreSQL 自身的进程都处于 D 状态,进入 D 状态发生在内核代码或者底层驱动代码中,典型的场景是与硬件进行通信。除了数据库自己的,一些操作系统的命令也处于 D 状态
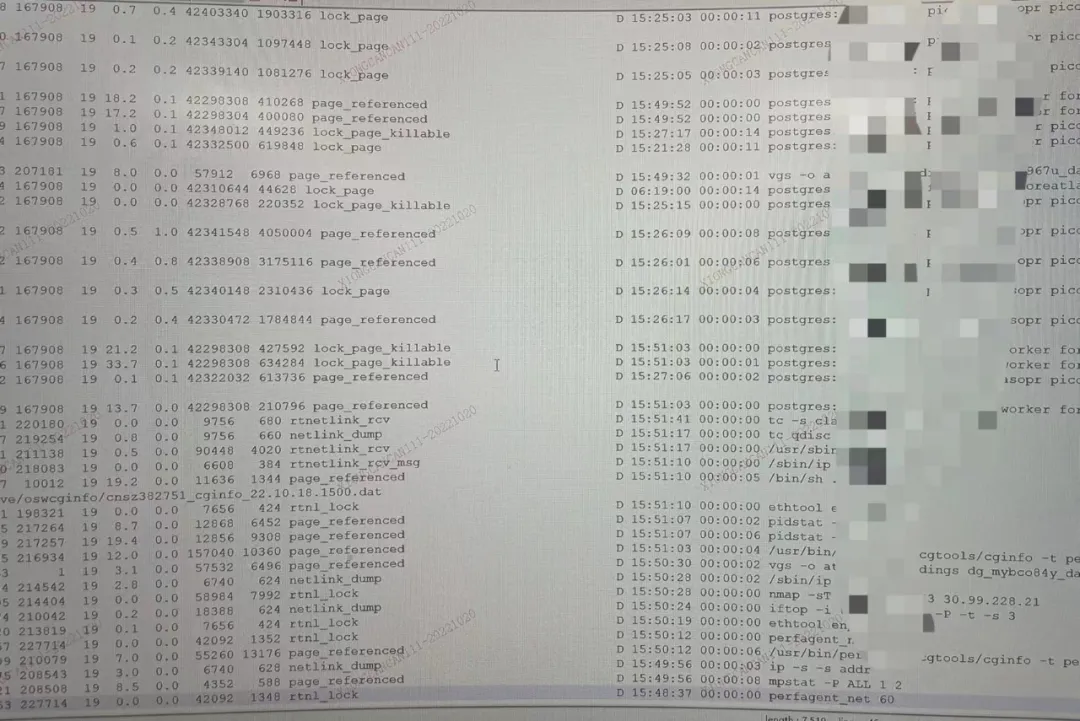
这些 D 状态的进程,包括 lock_page、lock_page_killable 、
page_reference 等等。
lock_page_killable
lock_page_killable 是 Linux 内核读取文件时会涉及到的,当 page cache 里面的数据和磁盘上的数据不一致时,需要先同步读取,这一步骤会加锁
// page cache中找到相关的page,但不是最新的的
page_not_up_to_date:
/* Get exclusive access to the page ... */
error = lock_page_killable(page);
if (unlikely(error))
goto readpage_error;
...
if (!PageUptodate(page)) {
/*
* 等待数据从磁盘读取完成后触发中断上来,最终唤醒该进程
*/
error = lock_page_killable(page);
if (unlikely(error))
goto readpage_error;
/*执行到这里,数据应该已经read完成了,如果期间没有新的脏数据的话,就应该是uptodate的数据了*/
if (!PageUptodate(page)) {
if (page->mapping == NULL) {
/*
* invalidate_mapping_pages got it
*/
/*释放锁*/
unlock_page(page);
page_cache_release(page);
goto find_page;
}
/*释放锁*/
unlock_page(page);
shrink_readahead_size_eio(filp, ra);
error = -EIO;
goto readpage_error;
}
/*释放锁*/
unlock_page(page);所以这个状态的进程和内存读写有关。
page_reference
而 page_reference 则是在内存回收时会用到的,此处可以参照之前的文章:PostgreSQL与内存,剪不断理还乱
页面回收时,会优先回收 INACTIVE 的页面,只有当 INACTIVE 页面很少时,才会考虑回收 ACTIVE 页面。为了评估页的活动程度,内核引入了 PG_referenced 和PG_active 两个标志位:
PG_referenced 代表最近是否被引用过,即引用的计数,每次访问了该页就加1
PG_active 代表当前活跃程度,如果页是活跃的就设置
是不是十分熟悉?和 PostgreSQL 自身的内存置换算法十分类似,不熟悉的去恶补一下吧 👉🏻 https://www.interdb.jp/pg/pgsql08.html
所以这个状态的进程也是和内存相关。还有 rpc_lock_page_killable,这个涉及到进程间通信,此进程在归档,因为我们是归档到 NAS 上的,默认也是先写到 page cache 就返回成功,再异步提交到 NAS Server。
以上种种状态,都表明和内存有关。
内存分析
那再分析一下内存。看看 vmstat
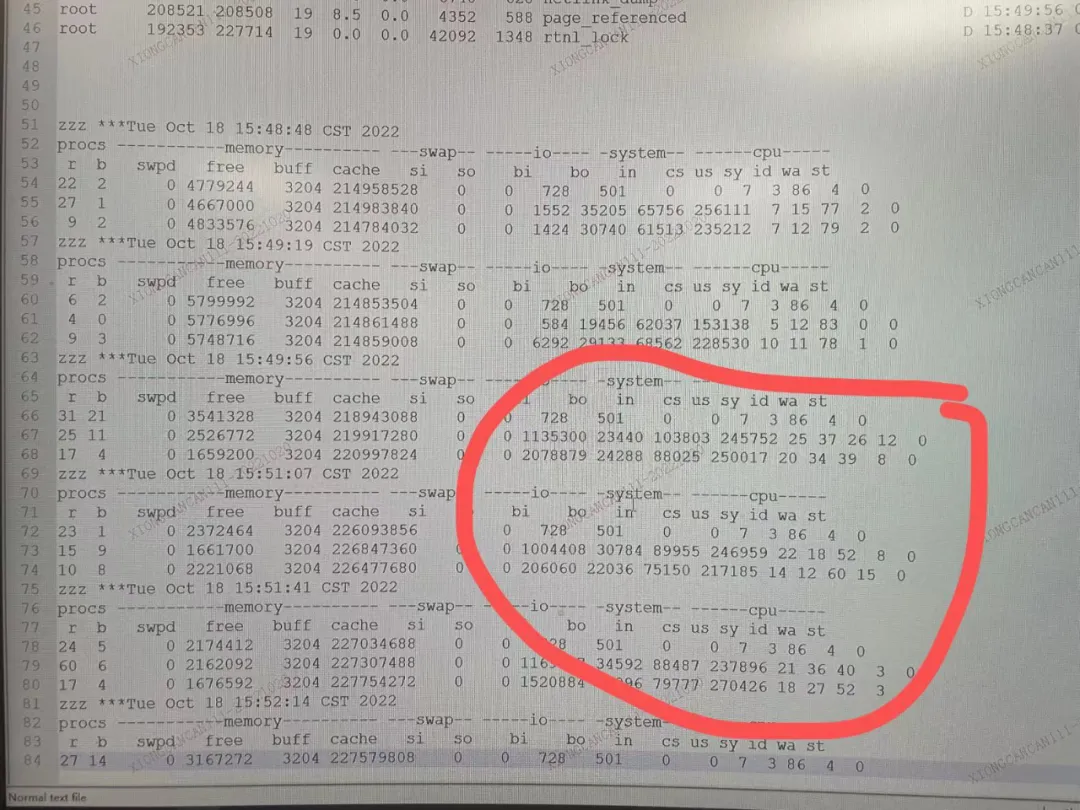
可以明显看到,到了15:50左右,bi/bo 陡增!而15:48的时候还只有1000多的量级,15:50就到了150万。
再看一下 sar,sar是我很喜欢的一个工具,看内存很方便,👇🏻 很明显了
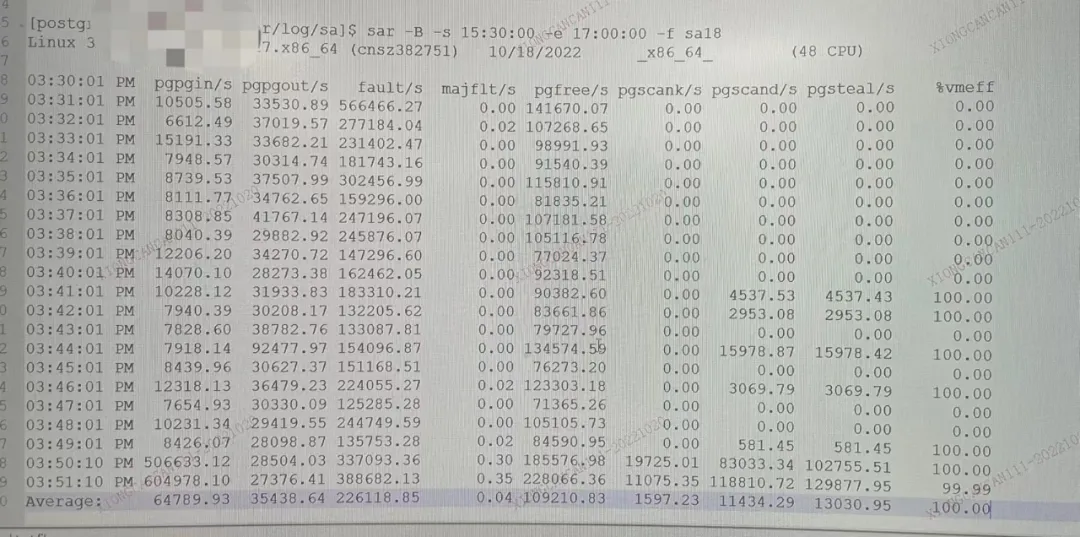
pgfree/s: Number of pages placed on the free list by the system per second.从free list回收的页数量
pgscank/s: Number of pages scanned by the kswapd daemon per second. kswap内存回收的页数量
pgscand/s: Number of pages scanned directly per second.直接内存回收的数量
pgsteal/s: Number of pages the system has reclaimed from cache (pagecache and swapcache) per second to satisfy its memory demands.每秒从page cache和swap cache中回收的页数量
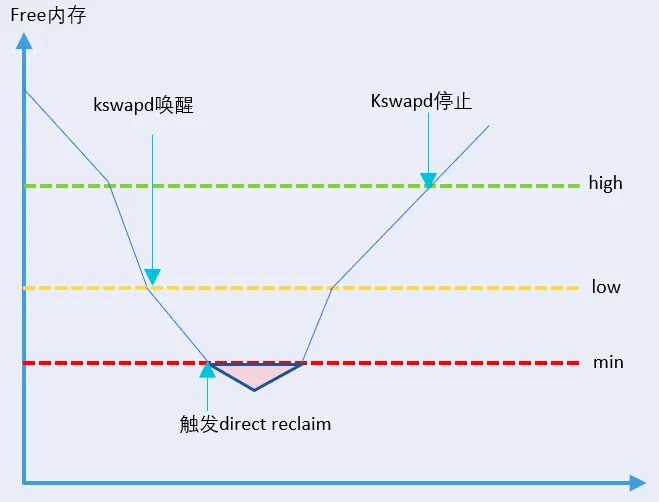
当整机free内存低于黄线low阈值时,内核的异步内存回收线程kswapd开始被唤醒,kswapd会在其他进程申请内存的同时回收内存。当整机free内存触达红线min阈值时,触发整机直接内存回收,所有来自用户空间的内存申请将被阻塞住,线程状态同时转换为D状态。此时只有来自内核空间的内存申请可以继续使用min值以下的free内存。后续当整机free内存逐步恢复到绿线high阈值以上后,kswapd线程停止内存回收工作。
可以清晰地看到,故障点pgscand和pgsteal都达到了10W的量级,每秒需要回收10万个页面,假如是脏页,还需要先回写至磁盘,因此这也说明了为什么前面vmstat看到 bi/bo 的值那么大,那个点大量内存回写,触发了大量的内存回收,并且还很糟糕,有 direct memory reclaim,进程会夯住,等待内存回收成功。
因此,到这里现象基本明了了,又双叒叕是内存的问题。
让我们再次通过 meminfo 来确认一下
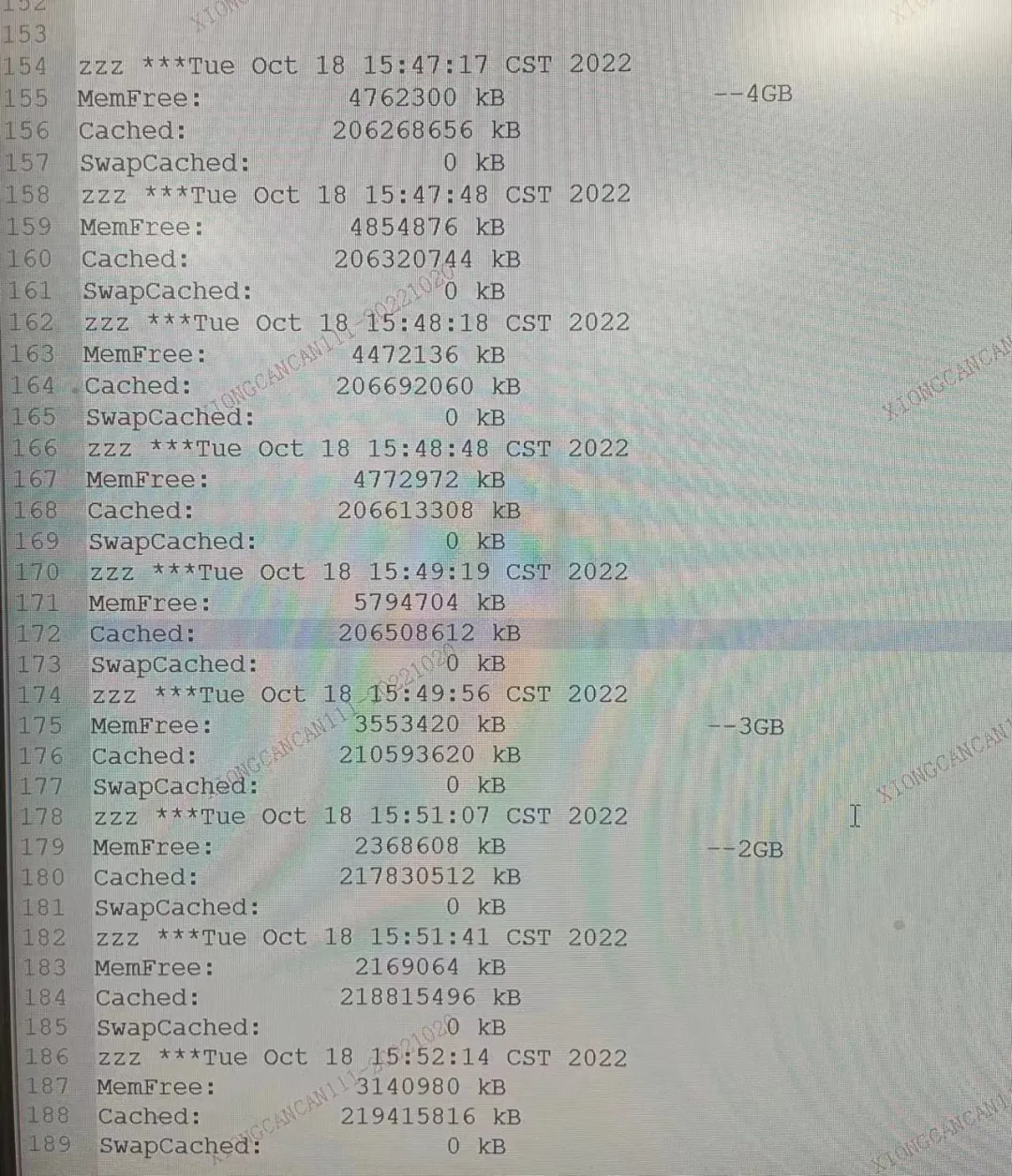
可以看到,故障点附近 Free 只有 2GB了,整机内存是 376 GB,大多数都是页缓存,达到了 220 GB。内核在内存将要耗尽时,会触发内存回收的工作,一般来说主要释放的是 Buffer/Cache 的内存,但是这种清缓存的操作也并不是没有成本。如果要清理缓存,那么必须要保证数据的一致性,所以一般在清理的时候同时会伴随这 IO 彪高。因为内核要对比内存中的数据和对应硬盘文件上的数据是否一致,如果不一致需要写回,之后才能回收。Linux内核的策略是最大程度的利用内存cache 文件系统的数据,提高IO速度,虽然在机制上是有进程需要更大的内存时,会自动释放Page Cache,但无法保证不会释放不及时或者释放的内存由于存在碎片不满足进程的内存需求,另外也存在缓存被写爆的情况。还可能出现一次性往磁盘写入过多数据,以致使系统卡顿。这些卡顿是因为系统认为,缓存太大用异步的方式来不及把它们都写进磁盘,于是切换到同步的方式写入。
因此假如这个时候来了高消耗的 SQL,压力一上来,可想而知。
通过查看数据库日志,果然在这个点,来了很多耗时 20s 的SQL,执行计划还是并行顺序扫描,并且还是个糟糕的pathman分区表,400个子表,😖,pathman 的问题在于会将配置信息加载到私有内存中。于是乎,当操作系统本身就在高压线附近的时候,任何一点风吹草动都可能是压死骆驼的最后一根稻草。不一会儿,主机夯死,数据库无法连接...
后续
既然知道了问题原因,措施也是有的,比如调整内存回写策略,默认的策略比较保守的
vm.dirty_background_ratio 是内存可以填充脏数据的百分比。这些脏数据稍后会写入磁盘,pdflush/flush/kdmflush这些后台进程会稍后清理脏数据。比如,我有32G内存,那么有3.2G的脏数据可以待着内存里,超过3.2G的话就会有后台进程来清理。
vm.dirty_ratio是可以用脏数据填充的绝对最大系统内存量,当系统到达此点时,必须将所有脏数据提交到磁盘,同时所有新的I/O块都会被阻塞,直到脏数据被写入磁盘。这通常是长I/O卡顿的原因,但这也是保证内存中不会存在过量脏数据的保护机制。
vm.dirty_background_bytes和vm.dirty_bytes是另一种指定这些参数的方法。如果设置bytes版本,则ratio版本将变为0,反之亦然。
vm.dirty_expire_centisecs 指定脏数据能存活的时间。当 pdflush/flush/kdmflush 在运行的时候,他们会检查是否有数据超过这个时限,如果有则会把它异步地写到磁盘中。毕竟数据在内存里待太久也会有丢失风险。
vm.dirty_writeback_centisecs 指定多长时间 pdflush/flush/kdmflush 这些进程会唤醒一次,然后检查是否有缓存需要清理。
另外还有大页/NUMA/SWAP等优化措施。
但是令人抓狂的是,由于我们DB组和主机组是分开的,主机组一直很抗拒去调整这些参数,觉得应用才是罪魁祸首,数据库哪能全部兜底,看样子又是需要很长一段时间的扯皮了。而且还存在一定的超分超卖,可能卖出去的规格达到了实际物理机内存的2倍,这也是令人头大的一个事情。
话说回来,内存导致 PostgreSQL 数据库故障的案例真是太多了 ...


评论