
PostgreSQL 基于 Pgpool 实现读写分离
文章选自:https://mp.weixin.qq.com/s/zpKp1SqFHW2V2_NQJvfd1A
Pgpool 的一些主要功能包括:
连接池:Pgpool在应用程序和数据库之间建立一个连接池,使得多个应用程序可以共享一组数据库连接,避免了重复的连接和断开。
负载均衡:Pgpool可以将客户端请求均衡地分配到多个PostgreSQL服务器上,以实现负载均衡和更好的性能。
高可用性:Pgpool可以检测到PostgreSQL服务器的故障,并自动将客户端请求重新路由到其他可用服务器,从而提高系统的可用性和稳定性。
并行查询:Pgpool可以将大型查询分成几个子查询,然后将这些子查询并行发送到多个PostgreSQL服务器上执行,以提高查询性能。
pgpool 即可。
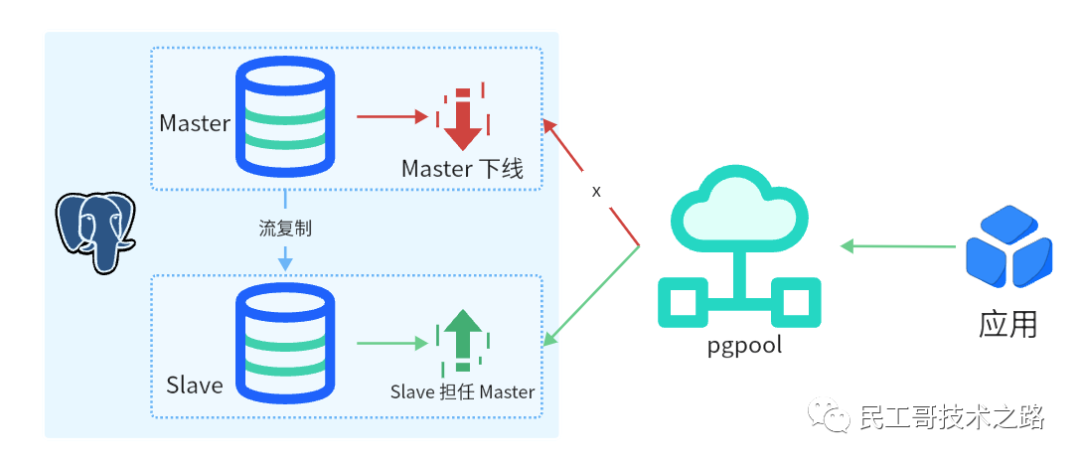
通过 pgpool 实现读写分离,写入操作由 Master 执行,读取操作由 Slave 执行。
由 repmgr 实现流复制,Master 数据自动复制到 Slave。
当 Master 遇故障下线时,由 repmgr 自定选择 Slave 为 Master,并继续执行写入操作。
当某个节点遇故障下线时,由 pgpool 自动断开故障节点的连接,并切换到可用的节点上。
环境准备
主从复制请看:
主机分配
OS:CentOS 7
节点1:master(192.168.36.130)
节点2:slave(192.168.36.131)
节点3:slave(192.168.36.133)
主从切换
手动切换
在上一节中,配置好了流复制结构,接下来模拟主库宕机,进行测试。
主库宕机
在master上执行
会发现测试库报错,连接不上主库。这时我们创建触发文件。
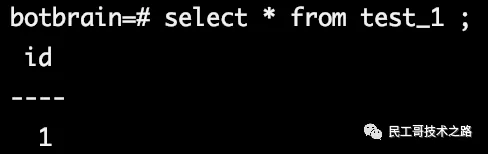
也可以放在别的目录,记得要给postgres权限。这时,测试库会变成主库。我们在slave上的测试库中新建测试表,并插入数据。
将主库的recover.done变为recovery.conf
启动主库
主库会自动的发现时间线的差异,并拷贝过来。登录主库查询,可以查到数据。
如果你们更改recovery.done,或者进行了别的操作,你会发现数据是不一样的。这是你需要停掉被恢复的库,手动同步时间线。
将主库的recover.done变为recovery.conf
再次启动主库。数据就已经同步了。
你可以多次手动切换进行测试,但是你会发现一个问题。触发文件trigger_file0每次在即创建完成后并不会存在,他在切换完成后就消失了。每次都要手动创建文件的话很麻烦,所以使用pgpool进行自动切换。
pgpool 自动切换
下载地址:http://www.pgpool.net/mediawiki/images/
解压编译安装
添加环境变量
配置pool_hba.conf
增加一下内容
配置pcp.conf和pool_passwd
master主节点登陆后执行:
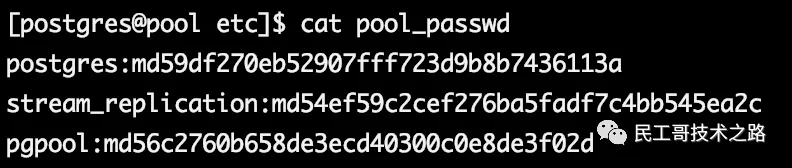
修改pool_passwd增加SQL执行结果的内容
形式为rolname:rolpassword 例如:postgres:md59df270eb52907fff723d9b8b7436113a

配置pgpool.conf
内容如下:根据自己的配置进行相应的修改
#CONNECTIONS
listen_addresses = '*'
port = 9999
socket_dir = '/opt/pgpool'
pcp_listen_addresses = '*'
pcp_port = 9898
pcp_socket_dir = '/opt/pgpool'
# - Backend Connection Settings -
backend_hostname0 = '192.168.36.130' #主库hosts
backend_port0 = 5432
backend_weight0 = 1
backend_data_directory0 = '/home/postgres/data' #数据库位置
backend_flag0 = 'ALLOW_TO_FAILOVER'
#
backend_hostname1 = '192.168.36.131' #从库hosts
backend_port1 = 5432
backend_weight1 = 1
backend_data_directory1 = '/home/postgres/data' #数据库位置
backend_flag1 = 'ALLOW_TO_FAILOVER'
#
# # - Authentication -
#
enable_pool_hba = on
pool_passwd = 'pool_passwd'
#
# # FILE LOCATIONS
#
pid_file_name = '/opt/pgpool/pgpool.pid' ##pid文件位置
logdir = '/data1/pg_logs' ##日志位置
#
replication_mode = off
load_balance_mode = on
master_slave_mode = on
master_slave_sub_mode = 'stream'
#
sr_check_period = 5
sr_check_user = 'pgpool' ##主库创建的用户
sr_check_password = '123' ##密码
sr_check_database = 'postgres'
#
# # HEALTH CHECK 健康检查
#
health_check_period = 10
health_check_timeout = 20
health_check_user = 'pgpool' ##主库创建的用户
health_check_password = '123' ##密码
health_check_database = 'postgres' ##检查的库
#
# # FAILOVER AND FAILBACK
# # 这是一个切换脚本,高可用全靠它
failover_command = '/data1/pg_bin/failover_stream.sh %d %H /tmp/trigger_file0' 给脚本放到指定位置,加执行权限。
failover_stream.sh内容:
# Failover command for streaming replication.
# This script assumes that DB node 0 is primary, and 1 is standby.
#
# If standby goes down, do nothing. If primary goes down, create a
# trigger file so that standby takes over primary node.
#
# Arguments: $1: failed node id. $2: new master hostname. $3: path to
# trigger file.
failed_node=$1
new_master=$2
trigger_file=$3
# Do nothing if standby goes down.
if [ $failed_node = 1 ]; then
exit 0;
fi
# Create the trigger file.
/usr/bin/ssh -T $new_master /bin/touch $trigger_file
exit 0;pgpool的启动和关闭
查看集群状态
测试(模拟master宕机)
关闭master数据库
pool
master关闭后,从节点的连接中断后又成功连接上
postgres=> show pool_nodes;
server closed the connection unexpectedly
This probably means the server terminated abnormally
before or while processing the request.
The connection to the server was lost. Attempting reset: Succeeded.
postgres=> show pool_nodes;
node_id | hostname | port | status | lb_weight | role | select_cnt | load_balance_node | replication_delay
---------+----------------+-------+--------+-----------+---------+------------+-------------------+-------------------
0 | 192.168.36.130 | 5432 | down | 0.500000 | standby | 0 | false | 0
1 | 192.168.36.131 | 5432 | up | 0.500000 | primary | 0 | true | 0
(2 rows)
slave成为新的主且slave中的recovery.conf 变成recovery.done
宕机后的恢复
最简单的方法就是将宕机的主库删掉,是用pg_basebackup的命令重新备份,但在生产环境中,数据量会越来越多,所以每次都重新拷贝很大的数据是很麻烦的,所以需要增量拷贝。
首先将master中的recovery.done改为recovery.conf,让它成为新的从库
启动宕机的数据库
使用pcp_attach_node命令
查看当前集群状态
恢复完成,master成为了新的standby。
读写分离
实现读写分离非常简单,在pgpool.conf中添加参数就可以实现。
pgpool会自动的将select语句分到从库上,将update等语句分到主库上。
PGPOOL 单点问题
pgpool自身就可以实现高可用,无需依赖其他插件。
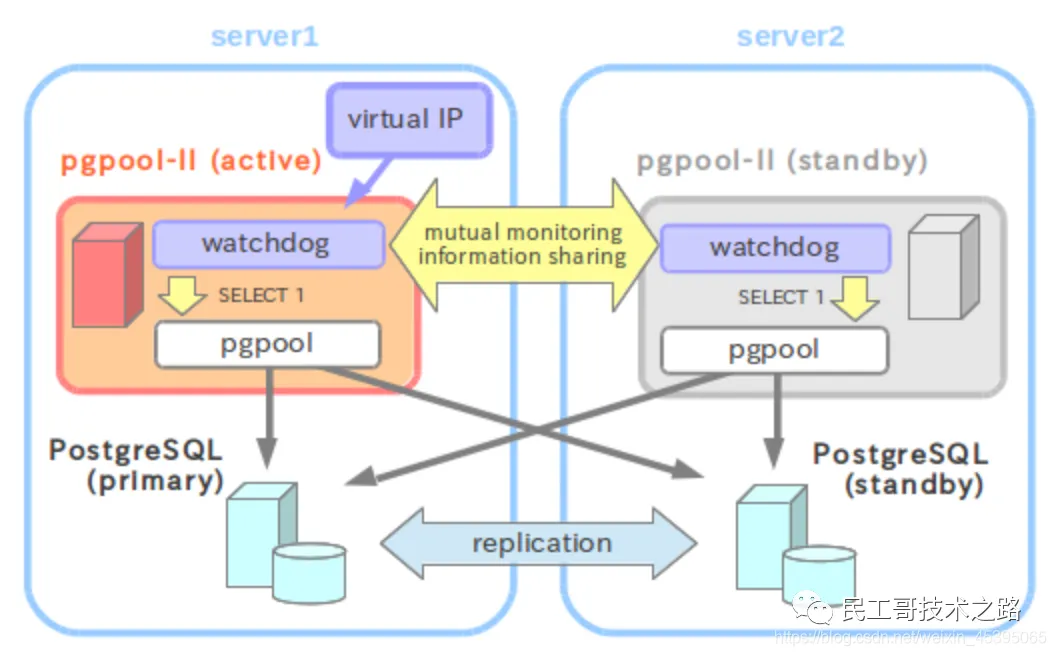
看门狗简介
“看门狗”是一个 pgpool-II 的子进程,用于添加高可用性功能。看门狗添加的功能包括:
pgpool 服务的生命检测
看门狗监控 pgpool 服务的响应而不是进程。它通过被它监控的 pgpool 发送查询到 PostgreSQL,并检查响应情况。
看门狗还监控到从 pgpool 到前端服务器的连接(例如应用服务器)。从 pgpool 到前端服务器的连接作为 pgpool 的服务来监控。
看门狗进程相互监控
看门狗进程交换被监控服务器的信息用来保证信息是最新的,并允许看门狗进程相互监控。
在某些故障检测中交换活跃/备用状态
当一个 pgpool 的故障被检测到,看门狗通知其他的看门狗这个消息。看门狗在旧的活跃 pgpool 发生故障后通过投票确定新的活跃 pgpool 并更新活跃/备用状态。
在服务器切换的时候实现自动虚拟 IP 地址分配
当一个备用 pgpool 服务器提升为活跃的,新的活跃服务器启动虚拟 IP 接口。也就是,之前的活跃服务器停用虚拟 IP 接口。这确保活动的 pgpool 使用相同的 IP 地址,即使在发生服务器切换的时候。
在恢复的时候自动注册服务器为备用服务器
当失效的服务器恢复或者新的服务器连接上来,看门狗进程通知其他的看门狗进程关于新服务器的信息, 看门狗进程在活跃服务器和其他服务器上接收这些信息。然后,新连接上的服务器注册为备用节点。
启动/停止看门狗
看门狗进程由 pgpool-II 自动启动/停止,也就是说,没有单独的命令来启动/停止它。但是,pgpool-II 启动时必须拥有管理员权限(root), 因为看门狗进程需要控制虚拟 IP 接口。
在等待到所有的 pgpool 启动后,生命监测将启动。所以在启动pgpool时使用root用户启动。
配置看门狗 (pgpool.conf)
看门狗的配置参数在 pgpool.conf 中配置。在 pgpool.conf.sample 文件中的 WATCHDOG 小节是配置看门狗的示例。以下所有的选项都是使用看门狗进程必须指定的。
基本配置
pgpool-II 的生命检查
虚拟 IP 地址
delegate_IP
#指定客户端服务器(应用服务器等)连接到的 pgpool-II 的虚拟 IP 地址(VIP)。当一个 pgpool 从备用切换到活跃状态,pgpool 将使用这个 VIP。
ifconfig_path
#本参数指定切换 IP 地址的命令所在的路径。只需要设置路径例如“/sbin”。
if_up_cmd
#本参数指定用于启用虚拟 IP 的命令。设置命令和参数例如:‘ifconfig eth0:0 inet KaTeX parse error: Expected group after '_' at position 4: _IP_̲ netmask 255.255.255.0’。KaTeX parse error: Expected group after '_' at position 4: _IP_̲ 将被 delegate_IP 指定的 IP 地址替换。
if_down_cmd
#本参数指定用于停用虚拟 IP 的命令。设置命令和参数例如:‘ifconfig eth0:0 down’。
arping_path
#本参数指定用于在虚拟 IP 切换后用于发送 ARP 请求的命令的所在路径。 只需要设置路径例如“/usr/sbin”。
arping_cmd
#本参数指定在进行虚拟 IP 切换后用于发送 ARP 请求的命令。设置命令和参数例如:‘arping -U KaTeX parse error: Expected group after '_' at position 4: _IP_̲ -w 1’。KaTeX parse error: Expected group after '_' at position 4: _IP_̲ 将被 delegate_IP 指定的 IP 地址替换。看门狗服务器自监控
4.1.5 监控服务器
配置文件
此配置基于文章前半部分进行,我将pgpool-slave放在了192.168.36.130上。
pgpool-master配置文件:
listen_addresses = '*'
port = 9999
pcp_listen_addresses = '*'
pcp_port = 9898
pcp_socket_dir = '/opt/pgpool'
backend_hostname0 = '192.168.36.130'
backend_port0 = 54321
backend_weight0 = 1
backend_data_directory0 = '/opt/psql/data'
backend_flag0 = 'ALLOW_TO_FAILOVER'
backend_hostname1 = '192.168.36.131'
backend_port1 = 54321
backend_weight1 = 1
backend_data_directory1 = '/opt/psql/data'
backend_flag1 = 'ALLOW_TO_FAILOVER'
enable_pool_hba = on
pool_passwd = 'pool_passwd'
pid_file_name = '/opt/pgpool/pgpool.pid'
logdir = '/data1/pg_logs'
replication_mode = off
load_balance_mode = on
master_slave_mode = on
master_slave_sub_mode = 'stream'
sr_check_period = 5
sr_check_user = 'pgpool'
sr_check_password = '123'
sr_check_database = 'postgres'
health_check_period = 10
health_check_timeout = 20
health_check_user = 'pgpool'
health_check_password = '123'
health_check_database = 'postgres'
failover_command = '/data1/pg_bin/failover_stream.sh %d %H /tmp/trigger_file0'
#之前是单节点的配置文件,解释在前面
#开启看门狗
use_watchdog = on
#本机的hosts或ip
wd_hostname = '192.168.36.133'
#看门狗的端口,默认9000
wd_port = 9000
#设置的vip
delegate_IP = '192.168.36.254'
if_cmd_path = '/sbin'
#对网卡操作的命令,网卡名根据自己的修改
if_up_cmd = 'ifconfig ens33:0 inet $_IP_$ netmask 255.255.255.0'
#对网卡操作的命令
if_down_cmd = 'ifconfig ens33:0 down'
#心跳检测端口
wd_heartbeat_port = 9694
#心跳检测间隔时间
wd_heartbeat_keepalive = 2
# 心跳信号的死区时间间隔
wd_heartbeat_deadtime = 30
#检测对方的hosts或ip
heartbeat_destination0 = '192.168.36.130'
#对方心跳检测端口
heartbeat_destination_port0 = 9694
#网卡名
heartbeat_device0 = 'ens33'
#其他pgpool的hosts或ip
other_pgpool_hostname0 = '192.168.36.130'
#其他pgpool的端口
other_pgpool_port0 = 9999
#其他端口
other_wd_port0 = 9000 方便对比和复制,下面是pgpool-slave的配置文件
listen_addresses = '*'
port = 9999
pcp_listen_addresses = '*'
pcp_port = 9898
pcp_socket_dir = '/opt/pgpool'
backend_hostname0 = '192.168.36.130'
backend_port0 = 54321
backend_weight0 = 1
backend_data_directory0 = '/opt/psql/data'
backend_flag0 = 'ALLOW_TO_FAILOVER'
backend_hostname1 = '192.168.36.131'
backend_port1 = 54321
backend_weight1 = 1
backend_data_directory1 = '/opt/psql/data'
backend_flag1 = 'ALLOW_TO_FAILOVER'
enable_pool_hba = on
pool_passwd = 'pool_passwd'
pid_file_name = '/opt/pgpool/pgpool.pid'
logdir = '/data1/pg_logs'
replication_mode = off
load_balance_mode = on
master_slave_mode = on
master_slave_sub_mode = 'stream'
sr_check_period = 5
sr_check_user = 'pgpool'
sr_check_password = '123'
sr_check_database = 'postgres'
health_check_period = 10
health_check_timeout = 20
health_check_user = 'pgpool'
health_check_password = '123'
health_check_database = 'postgres'
failover_command = '/data1/pg_bin/failover_stream.sh %d %H /tmp/trigger_file0'
use_watchdog = on
wd_hostname = '192.168.36.130'
wd_port = 9000
delegate_IP = '192.168.36.254'
if_cmd_path = '/sbin'
if_up_cmd = 'ifconfig ens33:0 inet $_IP_$ netmask 255.255.255.0'
if_down_cmd = 'ifconfig ens33:0 down'
wd_heartbeat_port = 9694
wd_heartbeat_keepalive = 2
wd_heartbeat_deadtime = 30
heartbeat_destination0 = '192.168.36.133'
heartbeat_destination_port0 = 9694
heartbeat_device0 = 'ens33'
other_pgpool_hostname0 = '192.168.36.133'
other_pgpool_port0 = 9999
other_wd_port0 = 9000pgpool的启动和关闭
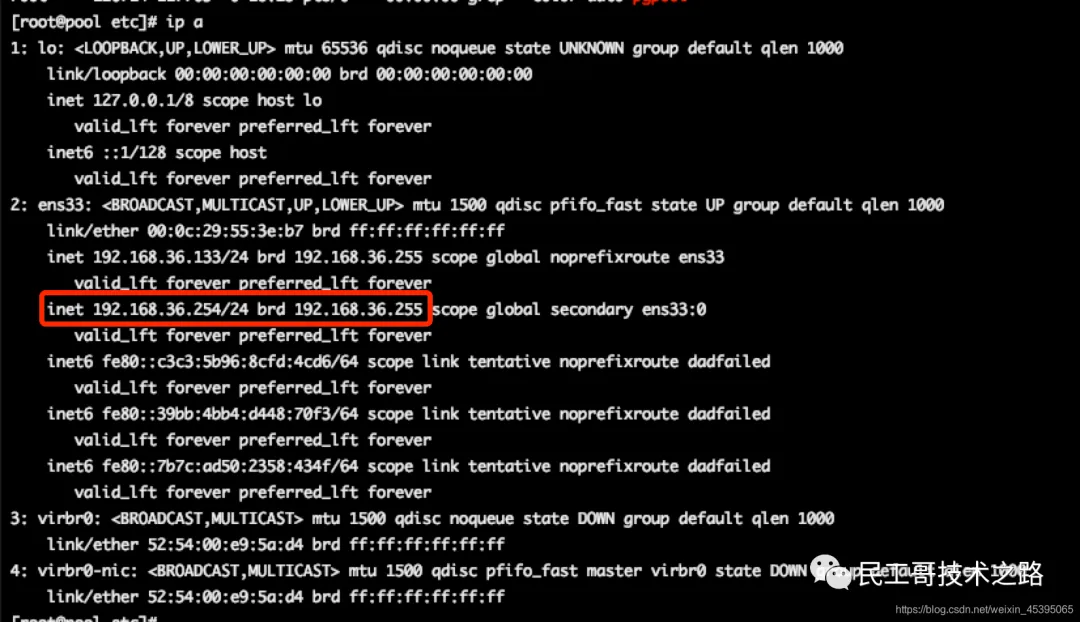
启动后的虚拟ip
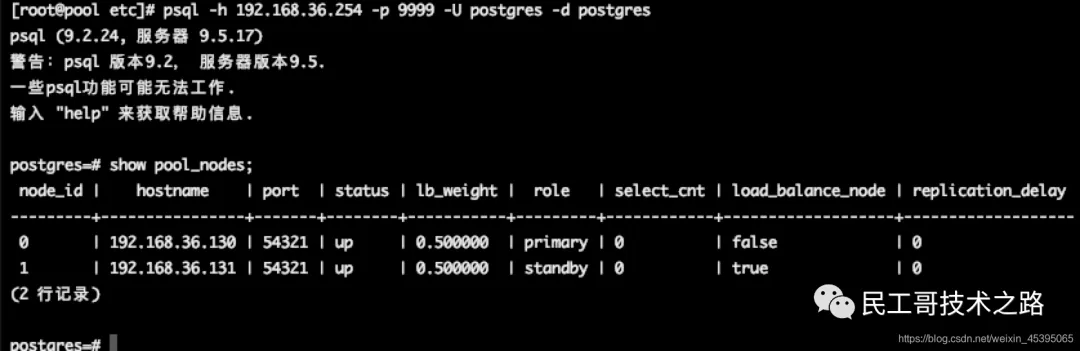
PG连接
使用vip进行连接就可以了


评论