
PostgreSQL的物理复制
1、背景
在9.0之前,通常依赖第三方工具和解决方案(如 Slony-I、Londiste、pgpool-II 和 Bucardo)来实现数据库复制和高可用性。从9.0开始,pg就开始支持物理复制,就是从实例级复制出一个与主库一模一样的从库(也叫备库)。有基于文件的拷贝和基于TCP流的数据传输(物理流复制)两种方式。两种方式都是传输 wal 数据,前者是等待生成一个完整的wal文件后,才会触发传输,后者是实时传输的。可以看出来基于文件方式的延迟会比较高,而且wal文件有可能没来得及传输就被损坏了,造成了这块的数据丢失。基于TCP流的方式延迟非常低,是现在最常见的方式。
基于文件的拷贝就是将实例数据文件拷贝到备库上,可以用pg_basebackup来实现,拷贝粒度为wal文件,所以数据会出现不一致的情况。
物理流复制就是在基于文件的拷贝的基础上,将主库的WAL Record 复制到从库,从库重放WAL Record来进行数据的恢复,拷贝粒度为wal record,可以极大保证数据的一致性。
物理复制只能针对实例级进行复制,就是复制单位为一个数据库实例,无法精确到数据库中某些表。物理复制分为同步复制和异步复制,异步复制就是主库上提交事务时必须等待备库接受WAL日志并写入到WAL文件中后才能返回成功,异步复制相反。
2、怎么使用物理复制
实现物理复制的详细步骤:
配置主服务器
首先,需要在主服务器上启用物理复制。编辑 postgresql.conf 文件,确保以下参数已正确配置:
wal_level = replica (wal日志的输出级别:minimal,replica,logical)
archive_mode = on (开启归档)
archive_command = '/bin/**' (wal日志归档命令)
max_wal_senders = 10 (主库上最大的wal发送进程数
wal_keep_segments = 512 (保留的最小wal日志的文件数)
hot_standby = on (数据库恢复过程中是否可读)
然后,编辑 pg_hba.conf 文件,添加允许从服务器连接的条目:
修改后需要重新加载配置文件
使用 pg_basebackup 创建基础备份
在从服务器上,使用 pg_basebackup 从主服务器创建基础备份:
配置从服务器
在从服务器的数据目录中,创建一个 recovery.conf 文件(在 PostgreSQL 12 及更高版本中,使用 standby.signal 文件代替):
对于 PostgreSQL 12 及更高版本,创建一个 standby.signal 文件,并在 postgresql.conf 中添加以下配置:
启动从服务器
验证复制
在从服务器上,检查复制状态:
在主服务器上,检查复制状态:
3、同步流复制和异步流复制
同步流复制:确保事务在主服务器和至少一个从服务器上都被写入 WAL 日志后才返回给客户端,提供更高的数据一致性,但会增加事务提交的延迟,对主服务器性能有一定影响。 异步流复制:主服务器提交事务后立即返回给客户端,不等待从服务器的确认,性能较高,但存在复制延迟,可能导致从服务器数据滞后于主服务器,在主服务器故障时可能会丢失一些数据。
postgresql.conf 配置文件中有两个参数 synchronous_commit 和 synchronous_standby_names。
synchronous_commit 意思是当前数据库提交事务时是否需要等待WAL日志写入磁盘后才向客户端返回成功,该参数的值有五种:on、off、local、remote_apply、remote_write。
单机环境:
on:本地wal先写入wal缓冲区,再写入wal文件中,也就是说必须等到wal写入到wal文件中后才能向客户端返回成功。
off:wal日志写入到wal 缓存中,不需要等待写到wal文件中就可以向客户端返回成功。
local:与on类似。
主备场景:
remote_write:主机事务提交时,需要等待备机接受的wal日志写到wal缓冲区之后才能提交。
remote_apply:主机事务提交时,需要等待备机接受的wal日志写到wal缓冲区,然后写入到备机的wal文件中,并且需要对wal日志执行之后才能提交。
另外一个参数synchronous_standby_names,这个参数是用来开启同步复制的,异步复制不需要开,参数值就是备机的application_name,这个在备库的recovery.conf中的primary_conninfo中设置。 当synchronous_standby_names设置了参数时,那就指定当前复制方式为同步复制,synchronous_commit参数决定了事务提交时主服务器需要等待的确认级别。不同值对性能的影响:off (async) > on (async) > remote_write (sync) > on|local (sync) > remote_apply (sync) 当synchronous_standby_names没有设置参数,默认使用异步复制模式。因为没有指定同步备用服务器,所以synchronous_commit:on、remote_apply、remote_write和local的设置都提供相同级别的同步级别:事务提交只等待本地刷新到磁盘。
4、物理流复制的工作过程
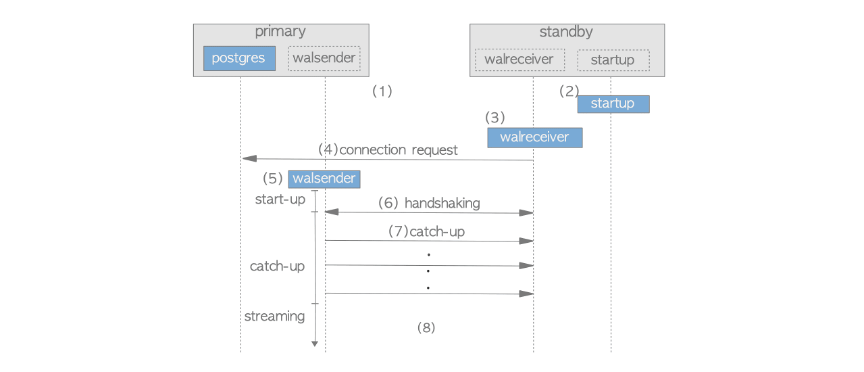
启动主服务器和备服务器。
备用服务器开始启动过程。
备用服务器启动walreceiver进程。
walreceiver向主服务器发送连接请求,如果主服务器没有运行,walreceiver会定期发送这些请求。
当主服务器收到连接请求时,启动一个walsender进程,walsender和walreceiver之间建立TCP连接。
walreceiver发送standby数据库集群最新的LSN(Log Sequence Number),在信息技术领域中,这被称为握手。
如果备用数据库的最新 LSN 小于主数据库的最新 LSN(备用数据库的 LSN<<主服务器的 LSN 上发送 WAL 数据 (WAL 数据来自主服务器的 LSN),walsender 将前一个 LSN 上的 WAL 数据发送到后一个 LSN。这些 WAL 数据由存储在主服务器的 pg_wal 子目录中的 WAL 段提供 (在 9.6 或更早的版本中,pg_xlog)。然后,备用服务器重放收到的 WAL 数据。在此阶段,备用服务器会追上主服务器,因此称为追赶(catch-up ) 。
流复制开始工作。
备库或者连接了wal接收器的应用程序的复制进度状态有四种:starup、catch-up、stream、backup。状态由wal发送进程维护。可以通过pg_stat_replication来进行查询当前备库的wal接收进程的复制状态。
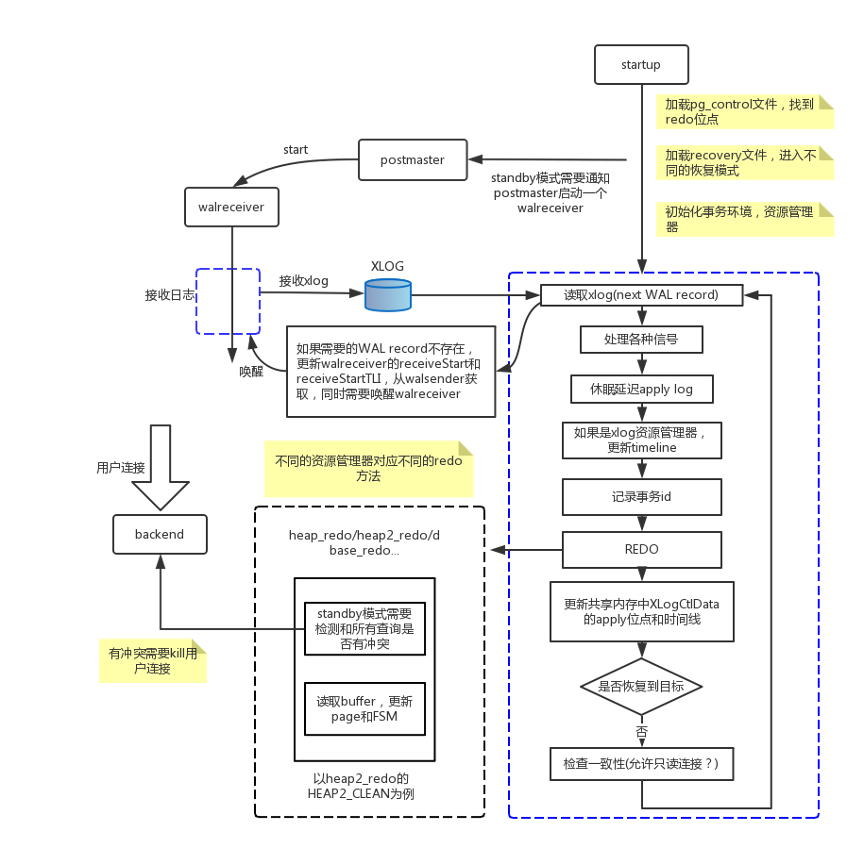
5、物理流复制的进程架构
物理流复制的核心部分由walsender,walreceiver和startup三个进程组成。 walsender进程是用来发送WAL日志记录的,执行顺序如下:
walreceiver进程是用来接收WAL日志记录的,执行顺序如下:
startup进程是用来apply日志的,执行顺序如下:
总体框架图: 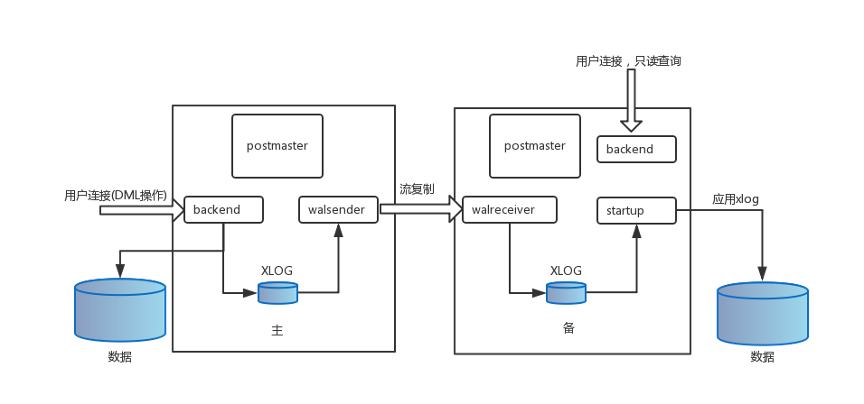
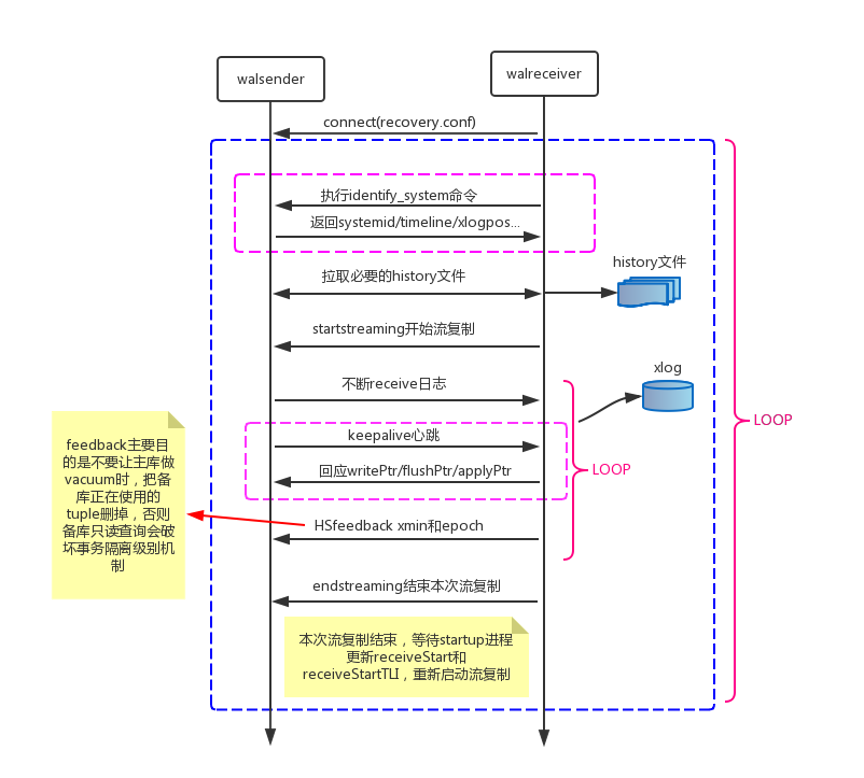
walsender和walreceiver交互主要分为以下几个步骤:
walreceiver启动后通过recovery.conf文件中的primary_conninfo参数信息连向主库,主库通过连接参数replication=true启动walsender进程;
walreceiver执行identify_system命令,获取主库systemid/timeline/xlogpos等信息,执行TIMELINE_HISTORY命令拉取history文件;
每个 postgresql 数据库在第一次初始化时,都会分配一个唯一的systemid。当配置主从复制时,从库需要将主库的数据备份过来,这时候也会拷贝systemid,所以从库和主库的systemid是一样的。主库处理IDENTIFY_SYSTEM请求时,会返回自身的systemid。从库通过匹配它,可以判断出来主库的有效性。比如当用户在配置时错写了主库的地址,就可以检查出来。
执行wal_startstreaming开始启动流复制,通过walrcv_receive获取WAL日志,期间也会回应主库发过来的心跳信息(接收位点、flush位点、apply位点),向主库发送feedback信息(最老的事务id),避免vacuum删掉备库正在使用的记录;
从库会定期向主库汇报自身的同步进度,比如已经刷新wal数据的位置,已经应用wal数据的位置等,这样主库就可以了解到每个从库的情况。当主库超过指定时间间隔,没有收到来自从库的消息,会发送Keepalive消息,强制要求从库汇报自身进度。
执行walrcv_endstreaming结束流复制,等待startup进程更新receiveStart和receiveStartTLI,一旦更新,进入步骤2。
startup进程进入standby模式和apply日志主要过程:
读取pg_control文件,找到redo位点;读取recovery.conf,如果配置standby_mode=on则进入standby模式。
如果是Hot Standby需要初始化clog、subtrans、事务环境等。初始化redo资源管理器,比如Heap、Heap2、Database、XLOG等。
读取WAL record,如果record不存在需要调用XLogPageRead->WaitForWALToBecomeAvailable->RequestXLogStreaming唤醒walreceiver从walsender获取WAL record。
对读取的WAL record进行redo,通过record->xl_rmid信息,调用相应的redo资源管理器进行redo操作。比如heap_redo的XLOG_HEAP_INSERT操作,就是通过record的信息在buffer page中增加一个record。还有部分redo操作(vacuum产生的record)需要检查在Hot Standby模式下的查询冲突,比如某些tuples需要remove,而存在正在执行的query可能读到这些tuples,这样就会破坏事务隔离级别。通过函数ResolveRecoveryConflictWithSnapshot检测冲突,如果发生冲突,那么就把这个query所在的进程kill掉。
检查一致性,如果一致了,Hot Standby模式可以接受用户只读查询;更新共享内存中XLogCtlData的apply位点和时间线;如果恢复到时间点,时间线或者事务id需要检查是否恢复到当前目标;
回到步骤3,读取next WAL record。
6、物理复制实验
前期准备
在两台腾讯云CVM上搭建PG实例,相关信息如下:
| 主机 | IP*地址* | OS | PG*版本* |
|---|---|---|---|
| 主节点 | 43.136.168.127 | CentOS 7.9 | 11.4 |
| 备节点 | 162.14.103.186 | CentOS 7.9 | 11.4 |
安装步骤:https://blog.csdn.net/sinat_42401704/article/details/127609394
主节点和备节点相关配置
1、新建归档目录
2、修改主库和备库配置文件postgresql.conf
这两个参数只需要在主节点上进行修改
3、创建一个测试用户
4、修改配置文件pg_hba.conf,在末尾添加下面内容
在备节点上执行
出现下面结果表示备份成生成: 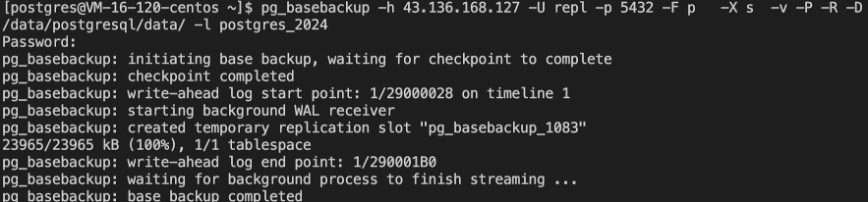
此时发现/data/postgresql/data中出现以下文件: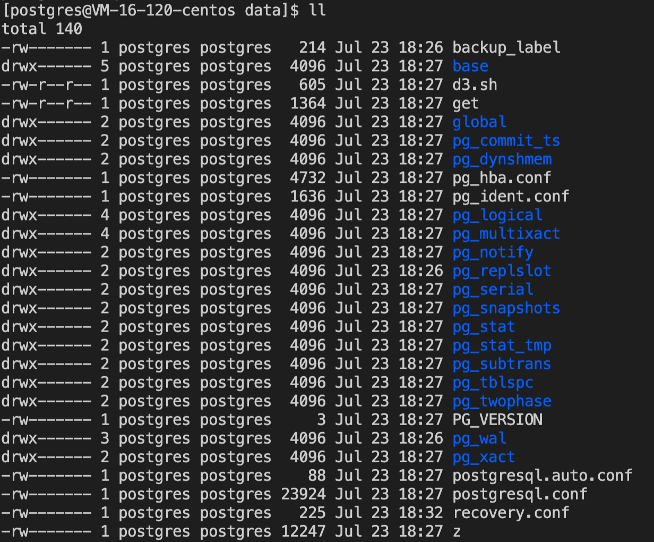
修改recovery.conf文件
重启备机的pg服务
在主节点上执行
新建表,并插入数据 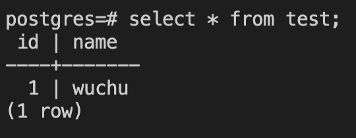
执行下面命令
显示当前备节点的同步状态 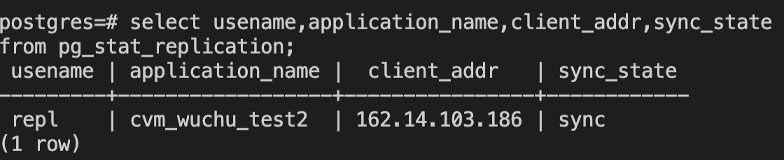
在备节点上查看
备节点数据已经跟主节点同步 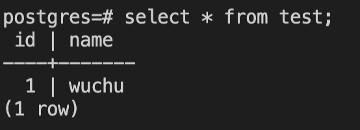
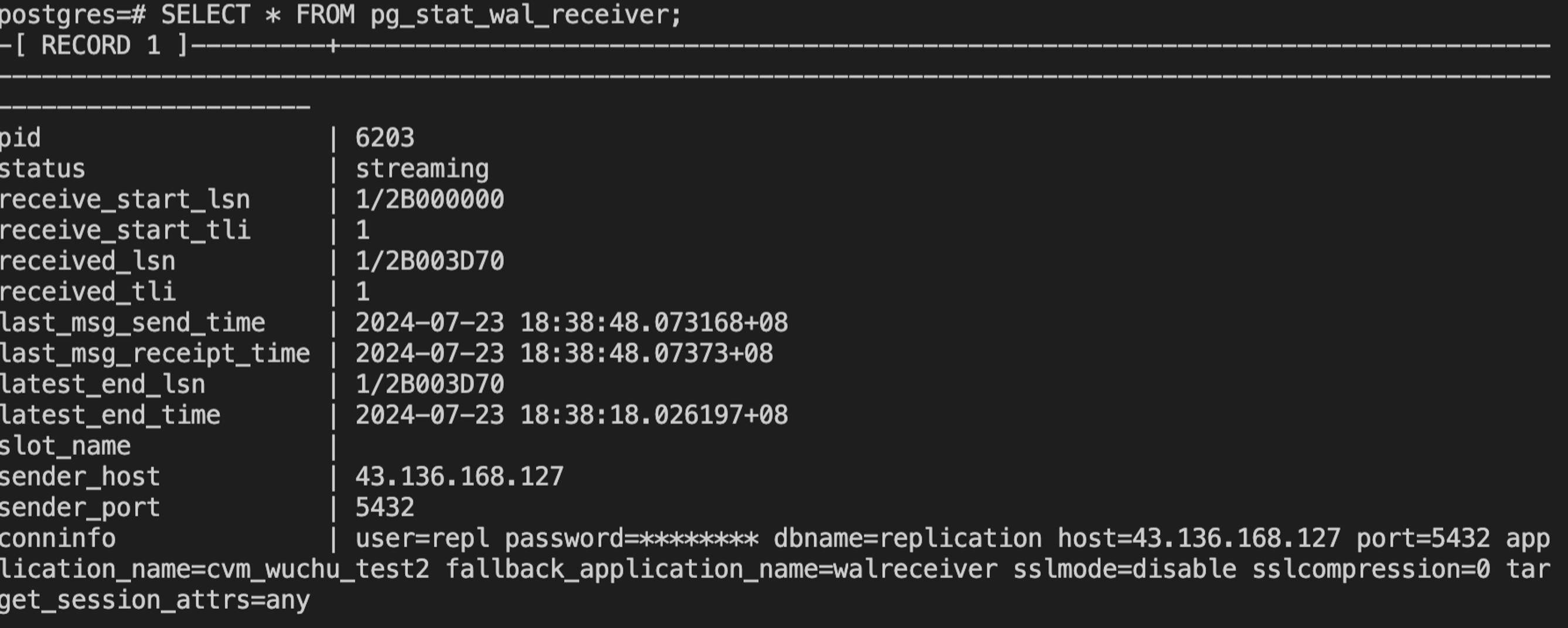
异步复制
上述实验设置主备之间是同步复制,修改下述参数进行异步复制 修改主节点的postgresql.conf文件:
在主机上执行命令发现备机的复制状态为async,已经变为异步复制模式 :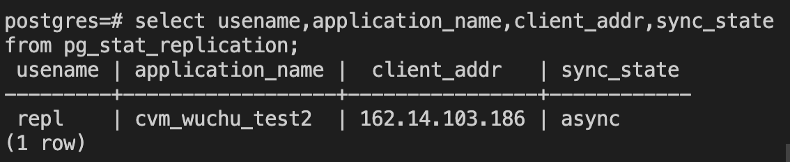


评论